메소드 이름으로 쿼리 생성
메소드 이름을 분석하여 JPQL 쿼리를 생성, 실행한다.
순수 JPA 사용
// MemberJpaRepository
public List<Member> findByUsernameAndAgeGrearterThan(String username, int age) {
return em.createQuery("select m from Member m where m.username = :username and m.age > :age", Member.class)
.setParameter("username", username)
.setParameter("age", age)
.getResultList();
}// MemberJpaRepositoryTest
@Test
public void findByUsernameAndAgeGrearterThan() {
Member m1 = new Member("AAA", 10);
Member m2 = new Member("AAA", 20);
memberJpaRepository.save(m1);
memberJpaRepository.save(m2);
List<Member> result = memberJpaRepository.findByUsernameAndAgeGrearterThan("AAA", 15);
Assertions.assertThat(result.get(0).getUsername()).isEqualTo("AAA");
Assertions.assertThat(result.get(0).getAge()).isEqualTo(20);
Assertions.assertThat(result.size()).isEqualTo(1);
}스프링 데이터 JPA 사용
// MemberRepository
public interface MemberRepository extends JpaRepository<Member, Long> {
List<Member> findByUsernameAndAgeGreaterThan(String username, int age);
}- 테스트 코드는 순수 JPA 사용 테스트 코드와 동일
- 스프링 데이터 JPA는 메소드 이름을 분석하여 JPQL을 생성, 실행한다.
쿼리 메소드 필터 조건
기본적인 메소드 이름 규칙은 조건은 By 다음에 구성하고 조건 컬럼 뒤에 비교문을 작성하지 않으면 '=' 비교로 동작한다. 그 외 조건은 스프링 데이터 JPA 문서 참고
스프링 데이터 JPA가 제공하는 쿼리 메소드 기능
- 조회 :
find...By, read...By, query...By, get...By - 건수 :
count...By(반환타입 Long) - Exists :
exists...By(반환타입 Boolean) - 삭제 :
delete...By, remove...By(반환타입 Long) - Distinct :
findDistinct..., findMemberDistinctBy... - Limit :
findFirst3, findFirst, findTop, findTop3
Limit 예제
public interface MemberRepository extends JpaRepository<Member, Long> {
List<Member> findTop5HelloBy();
}
※ 조건이 많아지면 JPQL을 직접 풀어서 구성 가능하다.
※ 엔티티 필드명이 변경되면 인터페이스에 정의한 메소드 이름도 꼭 변경해야 한다. 그렇지 않으면 애플리케이션 시작 시점에 오류가 발생한다. 애플리케이션 로딩 시점에 오류를 인지할 수 있는 것은 스프링 데이터 JPA의 큰 장점
JPA NamedQuery
@NamedQuery 어노테이션을 사용하여 쿼리를 정의하는 것으로 쉽게 생각하면 쿼리를 미리 정의하고 해당 쿼리에 이름을 붙여서 사용하는 것이다.
NamedQuery 정의
// Member
@NamedQuery(
name = "Member.findByUsername"
, query = "select m from Member m where m.username = :username"
)
public class Member {
...
}NamedQuery 호출
// 1. JPA 사용하여 호출
// MemberJpaRepository
public List<Member> findByUsername(String username) {
return em.createNamedQuery("Member.findByUsername", Member.class)
.setParameter("username", username)
.getResultList();
}
// 2. 스프링 데이터 JPA 사용하여 호출
// MemberRepository
@Query(name = "Member.findByUsername")
List<Member> findByUsername(@Param(value = "username") String username);- 스프링 데이터 JPA 사용시
@Query어노테이션을 생략하고 메소드 이름만으로 NamedQuery를 호출할 수 있다. 왜냐하면 기본 전략이선언한 도메인 클래스 + . + 메소드명으로 NamedQuery를 찾아 실행하는데 NamedQuery가 없으면 메소드명으로 쿼리 생성 전략을 사용하여 쿼리를 생성, 실행한다. (참고) - NamedQuery가 갖는 큰 장점 중 하나는 NamedQuery 문법에 오류가 있다면 애플리케이션 로딩 시점에 오류를 인지할 수 있다.
※ 스프링 데이터 JPA를 사용하면 실무에서 NamedQuery를 직접 등록하여 사용하는 일은 거의 없다. 대신 @Query 어노테이션을 사용하여 레포지토리 메소드에 쿼리를 직접 정의하여 사용한다.
@Query, 레포지토리 메소드에 쿼리 정의하기
// MemberRepository
@Query(value = "select m from Member m where m.username = :username and m.age = :age")
List<Member> findMember(@Param(value = "username") String username, @Param(value = "age") int age);@Query어노테이션 사용- 실행할 메소드에 정적 쿼리를 직접 작성하므로 이름없는 NamedQuery라고 할 수 있다.
- 애플리케이션 실행 시점에 오류 인지가 가능하다.
※ 실무에서는 조건이 많이 사용되므로 메소드 이름 전략보다는 @Query 어노테이션 사용을 더 자주한다.
@Query, 값, DTO 조회하기
// MemberRepository
@Query(value = "select m.username from Member m")
List<String> findUsernameList();
@Query(value = "select new study.datajpa.dto.MemberDto(m.id, m.username, t.name) from Member m join m.team t")
List<MemberDto> findMemberDto();- JPA 값 타입(
@Embedded)도 이 방식으로 조회할 수 있다. - DTO로 직접 조회 시 JPA의
new명령어로 생성자를 호출하여 사용한다.
단순 값 조회 결과

DTO 직접 조회 결과

파라미터 바인딩
쿼리 파라미터 바인딩을 위치 기반 / 이름 기반으로 할 수 있다.
-- 위치기반
select m from Member m where m.username = ?0
-- 이름기반
select m from Member m where m.username = :username- 위치기반 방식은 SQL에 파라미터 추가 및 변경에 따라 위치를 바꿔야 하기 때문에 오류가 발생할 수 있어 거의 사용하지 않는다.
컬렉션 파라미터 바인딩
@Query(value = "select m from Member m where m.username in :names")
List<Member> findByNames(@Param(value = "names") Collection<String> names);- Collection 타입으로 IN절을 지원한다.

반환 타입
스프링 데이터 JPA는 유연한 반환 타입을 지원한다. (참고)
// MemberRepository
List<Member> findListByUsername(String name); // 컬렉션
Member findMemberByUsername(String name); // 단건
Optional<Member> findOptionalByUsername(String name); // 단건 Optional- 컬렉션 반환 타입
- 결과 없을 경우 빈 컬렉션 반환 - 단건 반환 타입
- 결과 없을 경우 NULL 반환
- 결과가 2건 이상일 경우javax.persistence.NonUniqueResultException을 발생시키고 스프링 데이터 JPA가org.springframework.dao.IncorrectResultSizeDataAccessException으로 변환하여 발생시킨다.
※ 참고로 단건으로 지정한 메소드를 호출하면 스프링 데이터 JPA는 내부에서 JPQL의 Query.getSingleResult()를 호출한다. 이 메소드를 호출했을때 결과가 없으면 javax.persistence.NoResultException 예외가 발생하는데 스프링 데이터 JPA가 이 예외를 무시하고 NULL을 반환한다.
순수 JPA 페이징과 정렬
순수 JPA를 이용한 페이징과 정렬을 알아보자
// MemberJpaRepository
public List<Member> findByPage(int age, int offset, int limit) {
return em.createQuery("select m from Member m where m.age = :age order by m.username desc", Member.class)
.setParameter("age", age)
.setFirstResult(offset)
.setMaxResults(limit)
.getResultList();
}
public Long totalCount(int age) {
return em.createQuery("select count(m) from Member m where m.age = :age", Long.class)
.setParameter("age", age)
.getSingleResult();
}// MemberJpaRepositoryTest
@Test
public void paging() {
// given
memberJpaRepository.save(new Member("member1", 10));
memberJpaRepository.save(new Member("member2", 10));
memberJpaRepository.save(new Member("member3", 10));
memberJpaRepository.save(new Member("member4", 10));
memberJpaRepository.save(new Member("member5", 10));
int age = 10, offset = 0, limit = 3;
// when
List<Member> members = memberJpaRepository.findByPage(age, offset, limit);
long totalCount = memberJpaRepository.totalCount(age);
// then
Assertions.assertThat(members.size()).isEqualTo(3);
Assertions.assertThat(totalCount).isEqualTo(5);
}- 데이터베이스 방언을 기반으로 동작하기 때문에 데이터베이스에 맞는 페이징 쿼리가 실행된다.
스프링 데이터 JPA 페이징과 정렬
스프링 데이터 JPA를 이용한 페이징과 정렬을 알아보자
페이징과 정렬 파라미터
org.springframework.data.domain.Sort: 정렬 기능org.springframework.data.domain.Pageable: 페이징 기능(내부에 Sort 포함)
특별한 반환 타입
org.springframework.data.domain.Page: 추가 Count 쿼리 결과를 포함하는 페이징org.springframework.data.domain.Slice: 추가 Count 쿼리 없이 다음 페이지만 확인 가능(내부적으로limit + 1조회 방식으로 스크롤 시 데이터 로딩가능)List(자바 컬렉션) : 추가 Count 쿼리 없이 결과만 반환
Page 예제
// MemberRepository
Page<Member> findByAge(int age, Pageable pageable);// MemberRepositoryTest
@Test
public void paging() {
// given
memberRepository.save(new Member("member1", 10));
memberRepository.save(new Member("member2", 10));
memberRepository.save(new Member("member3", 10));
memberRepository.save(new Member("member4", 10));
memberRepository.save(new Member("member5", 10));
int age = 10;
PageRequest pageRequest = PageRequest.of(0, 3, Sort.by(Sort.Direction.DESC, "username"));
// when
Page<Member> result = memberRepository.findByAge(age, pageRequest);
// then
List<Member> content = result.getContent();
long totalElements = result.getTotalElements();
for (Member member : content) {
System.out.println("member = " + member);
}
System.out.println("totalElements = " + totalElements);
Assertions.assertThat(content.size()).isEqualTo(3);
Assertions.assertThat(result.getTotalElements()).isEqualTo(5);
Assertions.assertThat(result.getNumber()).isEqualTo(0);
Assertions.assertThat(result.getTotalPages()).isEqualTo(2);
Assertions.assertThat(result.isFirst()).isTrue();
Assertions.assertThat(result.hasNext()).isTrue();
}- 스프링 데이터 JPA는 페이지 인덱스가 1이 아닌 0부터 시작한다.
Page.content()로 조회 결과를 가져올 수 있고Page.getTotalElements()로 totalCount 결과를 가져올 수 있다.- Pageable은 인터페이스이며 실제 사용시엔 해당 인터페이스를 구현한
org.springframework.data.domain.PageRequest객체를 사용한다. - PageRequest의 생성자 파라미터 구성은 현재 페이지, 조회할 데이터 수이며 추가적으로 정렬 정보도 파라미터로 사용할 수 있다.
※ 참고로 정렬 조건이 복잡해지면 Sort 객체로 구현이 어렵기 때문에 사용하지 말고 쿼리에 정렬 조건을 작성하는 것이 더 효율적이다.



Slice 예제
// MemberRepository
Slice<Member> findByAge(int age, Pageable pageable);// MemberRepositoryTest
@Test
public void paging() {
// given
// Page 예제와 동일
// when
Slice<Member> result = memberRepository.findByAge(age, pageRequest);
// then
// Page 예제와 동일
}- Slice는 추가 Count 쿼리가 실행되지 않고 페이징 limit 값을
N + 1로 요청한다.

Count 쿼리 분리
데이터 조회 쿼리에 Left Outer Join을 사용했다고 추가 Count 조회 쿼리에도 사용할 필요가 없다. 왜냐하면 데이터 건수는 동일하기 때문이다. 이처럼 추가 Count 조회 쿼리가 데이터 조회 쿼리와 동일할 필요가 없고 성능의 영향도 있기 때문에 분리하여 구성, 사용할 수 있다.
// MemberRepository
// 추가 count 쿼리 분리
@Query(value = "select m from Member m left join m.team t"
, countQuery = "select count(m) from Member m"
)
Page<Member> findByAge(int age, Pageable pageable);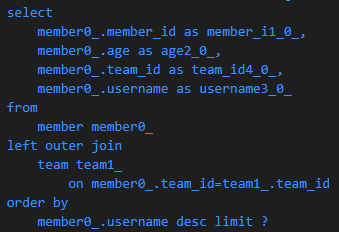
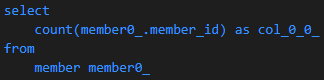
Top, First
Top, First도 동일하게 사용 가능하며 PageRequest를 전달하지 않으면 된다. (참고)
페이징을 유지하면서 엔티티를 DTO로 변환하기
API 사용시 Page를 그래도 반환하면 절대 안된다. Page를 map()을 사용하여 DTO로 변환하여 반환해야 한다.
// MemberRepositoryTest
@Test
public void paging() {
// given
// Page 예제와 동일
// when
Page<Member> result = memberRepository.findByAge(age, pageRequest);
// DTO 변환
Page<MemberDto> dtoResult = result.map(m -> new MemberDto(m.getId(), m.getUsername(), null));
// then
// Page 예제와 동일
}벌크성 수정 쿼리
JPA는 변경감지를 통해 트랜잭션 커밋 시점에 수정 쿼리가 실행되는데 이때 한건씩 실행이 되는데 좀 더 효율적으로 한번에 수정을 하기 위해 실행하는 수정 쿼리를 벌크성 수정 쿼리라 한다.
순수 JPA 사용
// MemberJpaRepository
public int bulkAgePlus(int age) {
return em.createQuery("update Member m set m.age = m.age + 1 where m.age >= :age")
.setParameter("age", age)
.executeUpdate();
}// MemberJpaRepositoryTest
@Test
public void bulkUpdate() {
// given
memberJpaRepository.save(new Member("member1", 10));
memberJpaRepository.save(new Member("member2", 19));
memberJpaRepository.save(new Member("member3", 20));
memberJpaRepository.save(new Member("member4", 21));
memberJpaRepository.save(new Member("member5", 30));
// when
int resultCount = memberJpaRepository.bulkAgePlus(20);
// then
Assertions.assertThat(resultCount).isEqualTo(3);
}executeUpdate()를 사용하여 쿼리를 실행하며 수정된 Row수가 반환된다.
스프링 데이터 JPA 사용
// MemberRepository
@Modifying(clearAutomatically = true)
@Query(value = "update Member m set m.age = m.age + 1 where m.age >= :age")
int bulkAgePlus(@Param("age") int age);// MemberRepositoryTest
@Test
public void bulkUpdate() {
// given
memberRepository.save(new Member("member1", 10));
memberRepository.save(new Member("member2", 19));
memberRepository.save(new Member("member3", 20));
memberRepository.save(new Member("member4", 21));
memberRepository.save(new Member("member5", 30));
// when
int resultCount = memberRepository.bulkAgePlus(20);
List<Member> result = memberRepository.findByUsername("member3");
Member findMember = result.get(0);
System.out.println("findMember = " + findMember);
// then
Assertions.assertThat(resultCount).isEqualTo(3);
}@Query,@Modifying어노테이션을 사용하여 쿼리를 실행하고 수정된 Row 수가 반환된다.@Modifying은executeUpdate()와 같다.@Modifying을 사용해야하는 수정, 삭제에서 사용하지 않을 경우 org.hibernate.hql.internal.QueryExecutionRequestException: Not supported for DML operations 오류가 발생한다.@Modifying(clearAutomaically = true)로 지정하면 벌크성 쿼리를 실행하고 나서 영속성 컨텍스트를 자동으로 초기화한다.
벌크연산 후 바로 조회 결과


벌크연산 시 주의할점
벌크연산을 하게되면 영속성 컨텍스트를 무시하고 바로 DB에 실행을 하기 때문에 영속성 컨텍스트에는 적용 되지 않는다. 그렇기 때문에 다시 데이터를 조회할 경우 영속성 컨텍스트의 값을 가져오기 때문에 벌크연산의 결과가 반영되지 않은 값이 조회된다. 벌크연산의 결과를 얻기 위해서는 벌크연산 후 영속성 컨텍스트를 초기화하거나 영속성 컨텍스트가 비어있는 상태에서 벌크연산을 먼저 실행해야 한다.
@EntityGraph
연관된 엔티티들을 SQL 한번에 조회하는 방법으로 JPA의 Fetch Join을 이해해야 한다.
// MemberRepository
@EntityGraph(attributePaths = {"team"})
@Query(value = "select m from Member m")
List<Member> findMemberEntityGraph();// MemberRepositoryTest
@Test
public void findMemberLazy() {
// given
// member1 -> teamA
// member2 -> teamB
Team teamA = new Team("teamA");
Team teamB = new Team("teamB");
teamRepository.save(teamA);
teamRepository.save(teamB);
memberRepository.save(new Member("member1", 10, teamA));
memberRepository.save(new Member("member2", 10, teamB));
em.flush();
em.clear();
// when
List<Member> members = memberRepository.findMemberEntityGraph();
// then
for (Member member : members) {
System.out.println("member = " + member);
System.out.println("member.team.class = " + member.getTeam().getClass());
System.out.println("member.team.name = " + member.getTeam().getName());
}
}- JPQL에
@EntityGraph어노테이션을 사용하여 Fetch Join을 추가할 수 있다.


@NamedEntityGraph
@NamedQuery와 동일한 기능을 하는 어노테이션이다.
@NamedEntityGraph(
name = "Member.all"
, attributeNodes = @NamedAttributeNode("team")
)
public class Member {}@EntityGraph(value = "Member.all")
@Query(value = "select m from Member m")
List<Member> findMemberEntityGraph();JPA Hint & Lock
Hint
- JPA 쿼리 힌트로 SQL 힌트가 아닌 JPA 구현체에게 제공하는 힌트
- JPA는 데이터 조회 시 조회 결과 원본과 변경감지용 사본(스냅샷)을 가지고 있다.
// MemberRepository
@QueryHints(value = @QueryHint(name = "org.hibernate.readOnly", value = "true"))
Member findReadOnlyByUsername(String string);// MemberRepositoryTest
@Test
public void queryHint() {
// given
Member member = new Member("member", 10);
memberRepository.save(member);
em.flush();
em.clear();
// when
// 읽기전용이기 때문에 변경감지가 일어나지 않아
// update SQL 미실행
Member findMember = memberRepository.findReadOnlyByUsername("member");
findMember.setUsername("member2");
em.flush();
}org.springframework.data.jpa.repository.QueryHints어노테이션 사용
Hint Page 예제
// MemberRepository
@QueryHints(value = @QueryHint(name = "org.hibernate.readOnly", value = "true"), forCounting = true)
Page<Member> findPagingByUsername(String name, Pageable pageable);// MemberRepositoryTest
@Test
public void queryHintPaging() {
// given
Member member = new Member("member", 10);
memberRepository.save(member);
em.flush();
em.clear();
PageRequest pageRequest = PageRequest.of(0, 3);
// when
Page<Member> findMember = memberRepository.findPagingByUsername("member", pageRequest);
for (Member m : findMember) {
// readOnly = true 여서 update 쿼리 미실행
m.setUsername("member2");
}
em.flush();
}forCounting: 반환 타입으로 Page 인터페이스를 적용하면 추가 Count 쿼리에도 쿼리 힌트를 적용한다. (기본값 :true)
Lock
// MemberRepository
@Lock(LockModeType.PESSIMISTIC_WRITE)
List<Member> findLockByUsername(String string);// MemberRepositoryTest
@Test
public void testLock() {
// given
Member member = new Member("member", 10);
memberRepository.save(member);
em.flush();
em.clear();
// when
List<Member> findMember = memberRepository.findLockByUsername("member");
em.flush();
}org.springframework.data.jpa.repository.Lock어노테이션 사용- JPA가 제공하는 기능을 스프링 데이터 JPA가
@Lock어노테이션으로 쉽게 사용할 수 있도록 제공
Lock 결과
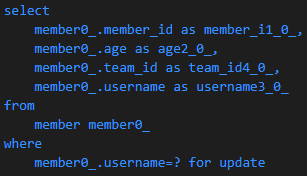
SELECT ~ FOR UPDATE 구문은 쉽게 말해서 조회한 특정 ROW에 대해 UPDATE가 종료될 때 까지 Lock 상태를 유지하여 다른 세션에서 접근이 불가능하고 UPDATE가 종료되면 Lock이 해제되는 것이다. (참고)
'Dev > Spring Data JPA' 카테고리의 다른 글
| [Spring Data JPA] 스프링 데이터 JPA 분석 (0) | 2021.12.14 |
|---|---|
| [Spring Data JPA] 확장 기능 (0) | 2021.12.13 |
| [Spring Data JPA] 공통 인터페이스 기능 (0) | 2021.11.29 |
| [Spring Data JPA] 예제 도메인 모델 (0) | 2021.11.29 |
| [Spring Data JPA] 프로젝트 환경설정 (0) | 2021.10.22 |
댓글