엔티티 매핑
- 객체와 테이블 매핑 :
@Entity,@Table - 필드와 컬럼 매핑 :
@Column - 기본 키 매핑 :
@Id - 연관관계 매핑 :
@ManyToOne,@JoinColumn
객체와 테이블 매핑
@Entity
- JPA가 관리하는 엔티티로 JPA를 이용해서 테이블과 매핑할 클래스에 어노테이션을 필수로 붙여준다.
- 특징
(1) 기본생성자 필수(파라미터가 없는publicorprotected생성자)
(2)final 클래스, enum, interface, inner 클래스에는 사용 불가
(3) 저장할 필드에final사용 불가 - 속성으로
name이 있으며 JPA에서 사용할 엔티티 이름을 지정하며, 기본값은 클래스 이름이고 같은 클래스 이름이 없으면 가급적 기본값을 사용한다.
@Table
- 엔티티와 매핑할 테이블을 지정하는 어노테이션
- 속성
(1)name: 매핑할 테이블 이름 (기본값: 엔티티 이름)
(2)catalog: DBcatalog매핑
(3)schema: DBschema매핑
(4)uniqueConstraints: DDL 생성 시에 유니크 제약 조건 생성
데이터베이스 스키마 자동 생성
스키마 자동 생성
애플리케이션 실행 시점에 데이터베이스 방언을 활용하여 DDL을 자동 생성하는 것으로 테이블 중심에서 객체 중심으로 설계, 사용이 가능한 장점이 있으며 주의할 점으로는 생성된 DDL은 개발 서버에서만 사용하고 운영 서버에는 사용하지 않거나 적절히 다듬은 뒤 사용해야 한다.
hibernate.hbm2ddl.auto
데이터베이스 스키마 자동 생성을 위한 옵션으로 persistence.xml에 추가하여 제어한다.
create: 기존테이블 삭제 후 다시 생성 (drop+create)create-drop:create와 같으나 종료시점에 테이블dropupdate: 변경분만 반영 (운영 DB에는 사용하면 안됨) -> 컬럼 삭제는 불가validate: 엔티티와 테이블이 정상 매핑되었는지만 확인none: 사용하지 않음
스키마 자동 생성 시 주의 사항
- 운영 서버에는 절대
create,create-drop,update,validate전부 사용하지 않는 것이 좋다. 왜냐하면 운영 서버에서 애플리케이션 계정으로 DDL을 보내는 것은 매우 위험하다. - 개발 초기 단계는
create또는update를 사용한다. - 테스트 서버는
update또는validate를 사용한다. - 스테이징(운영 데이터의 덤프를 떠서 데이터까지 운영과 비슷한 환경) 서버는
validate또는none을 사용한다.
DDL 생성 기능
- 제약조건 추가 : 필수 및 기본키, 컬럼 사이즈 지정
@Column(unique = true, nullable = false, length = 10) - 유니크 제약조건 추가
@Table(uniqueConstraints = {@UniqueConstraint(name = "NAME_AGE_UNIQUE", columnNames = {"NAME", "AGE"})}) - DDL 생성 기능은 DDL을 자동 생성할 때만 사용되고 JPA의 실행 로직에는 영향을 주지 않는다.
필드와 컬럼 매핑
매핑 어노테이션 종류
@Column: 컬럼 매핑@Enumerated:enum타입 매핑@Temporal: 날짜 타입 매핑@Lob:BLOB, CLOB타입 매핑@Transient: 특정 필드를 컬럼에 매핑하지 않음 (매핑 무시)
@Column
| 속성 | 설명 | 기본값 |
| name | 필드와 매핑할 테이블의 컬럼명 | 객체의 필드명 |
| insertable / updatable | 등록, 변경 가능 여부 | true |
| nullable (DDL) | null 값 허용 여부 설정, false 설정 시 DDL 생성 시에 not null 제약조건 추가 |
|
| unique (DDL) | @Table의 uniqueConstraints와 같지만 한 컬럼에 간단히 유니크 제약조건 추가 (복합 컬럼은 불가, 제약조건 명이 임의의 값으로 지정) |
|
| columnDefinition (DDL) | DB 컬럼 정보를 직접 줄 수 있다.ex) varchar(100) default 'empty' |
필드의 자바 타입과 방언 정보를 사용 |
| length (DDL) | 문자 길이 제약조건으로 String 타입에만 사용한다. | 255 |
| precesion, scale (DDL) | BigDecimal 타입에서 사용(BigInteger도 가능)하며 precision은 소수점을 포함한 전체 자릿수, scale은 소수의 자릿수이다. 참고로 double, float 타입에는 적용되지 않으며 아주 큰 숫자나 정밀한 소수를 다루어야 할 때만 사용한다. |
@Enumerated
EnumType.ORDINAL:enum순서(값 명시 순서) 를 DB에 저장EnumType.STRING:enum이름(값)을 DB에 저장
※ 기본값은 ORDINAL이지만 ORDINAL은 사용하지 말아야 한다. 왜냐하면 enum 값 변동 시 순서에 변경이 있어서 값으로 저장해야 구별이 가능하다.
@Temporal
TemporalType.DATE: 날짜 값으로 DB의DATE타입과 매핑 (예, 2013-10-11)TemporalType.TIME: 시간 값으로 DB의TIME타입과 매핑 (예, 11:11:11)TemporalType.TIMESTAMP: 날짜와 시간 값으로 DB의TIMESTAMP타입과 매핑 (예, 2013-10-11 11:11:11)
※ Java 8 이상에서 @Temporal 어노테이션을 사용하지 않고도 LocalDate, LocalDateTime 타입을 사용하여 필드를 만들 경우 자동으로 DATE, TIMESTAMP 타입으로 매핑한다.
@Lob
지정 가능한 속성이 없고 매핑할 필드가 문자(String, char[], java.sql.CLOB)면 CLOB 나머지(byte[], java.sql.BLOB)는 BLOB 타입으로 매핑
@Transient
필드를 매핑하고 싶지 않을 경우 사용하며 DB에 저장 및 조회가 불가능하여 주로 메모리상에서만 임시로 값을 보관하고 싶을 때 사용한다.
필드와 컬럼 매핑 동작 확인
소스
(1) Member.java
@Entity
public class Member {
@Id // DB PK
private Long id;
@Column(name = "name") // DB 컬럼명은 name
private String username;
private Integer age;
@Enumerated(EnumType.STRING)
private RoleType roleType;
@Temporal(TemporalType.TIMESTAMP) // 3가지 DATE, TIME, TIMESTAMP 존재
private Date createdDate;
@Temporal(TemporalType.TIMESTAMP)
private Date lastModifiedDate;
@Lob // CLOB
private String description;
public Member() {}
}(2) persistence.xml
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.2" xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd">
<persistence-unit name="hello">
<properties>
<!-- 필수 속성 -->
<property name="javax.persistence.jdbc.driver" value="org.h2.Driver" />
<property name="javax.persistence.jdbc.user" value="sa" />
<property name="javax.persistence.jdbc.password" value="" />
<property name="javax.persistence.jdbc.url" value="jdbc:h2:tcp://localhost/~/test" />
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect" />
<!-- 옵션 -->
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.format_sql" value="true" />
<property name="hibernate.use_sql_comments" value="true" />
<property name="hibernate.jdbc.batch_size" value="10" />
<property name="hibernate.hbm2ddl.auto" value="create" /> <!-- DDL 자동 생성 -->
</properties>
</persistence-unit>
</persistence>결과

기본 키 매핑
매핑 방법
- 직접 할당 :
@Id만 사용 - 자동 생성 :
@GeneratedValueIDENTITY: DB에 위임, MySQLSEQUENCE: DB 시퀀스 오프젝트 사용, Oracle (@SequenceGenerator필요)TABLE: 키 생성용 테이블 사용, 모든 DB에서 사용 (@TableGenerator필요)AUTO: 방언에 따라 자동 지정, 기본값
IDENTITY
기본 키 생성을 DB에 위임하는 것으로 주로 MySQL, PostgreSQL, SQL Server, DB2에서 사용한다. (예, MySQL의 AUTO_INCREMENT)
※ JPA는 보통 트랜잭션 커밋 시점에 insert SQL을 실행하는데 AUTO_INCREMENT는 DB에 insert SQL을 실행 한 후에 ID 값을 알 수 있다. 따라서 IDENTITY 전략은 EntityManager.persist() 시점에 즉시 insert SQL을 실행(트랜잭션 커밋을 하지 않고도) 하고 DB에서 식별자를 조회하여 사용한다. 그렇기 때문에 영속성 관리에서 배웠던 것 처럼 insert SQL을 모아서 한번에 실행이 불가능한 단점이 있다.
예제 소스
(1) Member.java
@Entity
public class Member {
@Id // DB PK
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
}(2) JpaMain.java
public class JpaMain {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
// ID는 자동생성 되기 때문에 셋팅 제외
Member memberA = new Member();
member.setUsername("A");
Member memberB = new Member();
member.setUsername("B");
em.persist(memberA);
em.persist(memberB);
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}
emf.close();
}
}동작 결과


SEQUENCE
DB 시퀀스는 유일한 값을 순서대로 생성하는 특별한 DB 오브젝트로 주로 Oracle, PostgreSQL, DB2, H2 DB에서 사용한다. (예, Oracle의 SEQUECNE)
※ 시퀀스를 지정할 컬럼의 자료형은 숫자형이어야 한다. (int는 0이 있어서 불가, Integer도 10억자리 넘으면 초기화되어 불가능하여 주로 Long 사용)
※ EntityManager.persist(entity) 이전에 시퀀스를 호출하고 설정한 PK를 호출하여 사용하면 insert SQL을 모아서 실행 가능하다.
@SequenceGenerator
| 속성 | 설명 | 기본값 |
| name | 식별자 생성기 이름 | 필수 |
| sequenceName | DB에 등록되어 있는 시퀀스 이름 | hibernate_sequence |
| initialValue | DDL 생성 시에만 사용되는 것으로 시퀀스 DDL을 생성할 때 처음 1 시작하는 수를 지정 | 1 |
| allocationSize | 시퀀스 한번 호출에 증가하는 수(성능 최적화에 사용됨, DB 시퀀스 값이 하나씩 증가하도록 설정되어 있으면 이 값을 반드시 1로 설정) | 50 |
| catalog, schema | DB catalog, schema 이름 |
예제 소스
(1) Member.java
@Entity
@SequenceGenerator(
name = "member_seq_generator"
, sequenceName = "member_seq"
, initialValue = 1, allocationSize = 1)
public class Member {
@Id // DB PK
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "member_seq_generator")
private Long id;
public Member() {}
}(2) JpaMain.java
public class JpaMain {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
// ID는 자동생성 되기 때문에 셋팅 제외
Member memberB = new Member();
member.setUsername("B");
Member memberC = new Member();
member.setUsername("C");
em.persist(memberB);
em.persist(memberC);
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}
emf.close();
}
}동작 결과


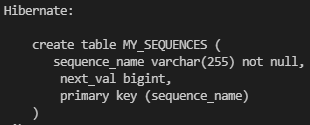
TABLE
키 생성 전용 테이블을 하나 만들어서 DB 시퀀스를 흉내내는 전략으로 모든 DB에 적용 가능한 장점이 있지만 최적화가 되어있지 않기 때문에 성능면에서 단점이 있다.
@TableGenerator
| 속성 | 설명 | 기본값 |
| name | 식별자 생성기 이름 | 필수 |
| table | 키생성 테이블명 | hibernate_sequences |
| pkColumnName | 시퀀스 컬럼명 | sequence_name |
| valueColumnName | 시퀀스 값 컬럼명 | next_val |
| pkColumnValue | 키로 사용할 값 이름 | 엔티티 이름 |
| initialValue | 초기값, 마지막으로 생성된 값이 기준이다. | 0 |
| allocationSize | 시퀀스 한 번 호출에 증가하는 수 (성능 최적화에 사용) | 50 |
| catalog, schema | DB catalog, schema 이름 | |
| uniqueConstraints (DDL) | 유니크 제약 조건을 지정할 수 있다. |
예제 소스
// Member.java
@Entity
@TableGenerator(
name = "member_seq_generator"
, table = "MY_SEQUENCES"
, pkColumnValue = "member_seq"
, allocationSize = 1)
public class Member {
@Id // DB PK
@GeneratedValue(strategy = GenerationType.TABLE, generator = "member_seq_generator")
private Long id;
public Member() {}
}
동작 결과

Sequence, Table Generator 의 성능 최적화
Sequence, Table Generator의 속성 중 allocationSize를 이용해 성능 최적화를 할 수 있다.
방식은 다음과 같다.
- 기본값(50) 설정 시 최초 시퀀스 호출 시 50개의 시퀀스를 받아서 메모리에 올려 사용한다.
- 사용 중 50번까지 다 사용하면 한번 더 DB에서 시퀀스를 호출하여 다음 50개의 시퀀스를 받아서 동일하게 사용한다.
따라서 시퀀스 호출은 최초 값 호출 1번과 allocationSize + 1 만큼의 값 호출 1번, 총 2번이 실행되며
그 뒤 allocationSize + 1 값에 도달하면 다시 추가적인 allocationSize 만큼의 값 호출을 한다.
그렇다면 'allocationSize 를 최대로 하면 성능이 더 좋아질까?' 라는 생각에는 서버 재기동 시 중간의 값이 비어버리는 현상이 발생할 수 있어 최대로 한다고 무조건 좋지는 않다.
권장하는 식별자 전략
우리가 알고 있는 기본키 제약 조건이라 하면 null이 아니고, 유일해야 하며 변하면 안되는 값이 기본키가 되야 한다고 알고 있는데 미래까지 이 조건을 만족하는 자연키는 찾기가 어렵다. 따라서 권장하는 방법은 Long형 + 대체키 + 키 생성전략을 사용하는 것이 적합하다고 생각한다.
'Dev > JPA' 카테고리의 다른 글
| [JPA] 연관관계 매핑 기초 (0) | 2021.08.12 |
|---|---|
| [JPA] 실습 - 요구사항 분석과 기본 매핑 (0) | 2021.08.03 |
| [JPA] 영속성 관리 (0) | 2021.07.20 |
| [JPA] JPA 시작하기 (0) | 2021.07.17 |
| [JPA] JPA 소개 (0) | 2021.07.13 |
댓글